Modern Data Stack
Learn more about how data teams are evolving their data pipelines.
or try it free. We’re open source! Install Now
Grouparoo is the Reverse ETL Tool that meets you where you are.
🔎 Use the records and segments you already have
The modern data stack lets you use the robust Record data you've already made in your data warehouse.
🎁 You own your source of truth
In the modern data stack, all of your relevant data is housed in your data warehouse.
🧭 Connect products, analytics, and operations
Having your data in a data warehouse is powerful. Making it accessible in the applications you use every day is even more powerful.
📈 Quick and predictable data flow
The modern data stack provides solutions that are predictable and simple, keeping your data flow clear.
What is the modern data stack and why is it important?
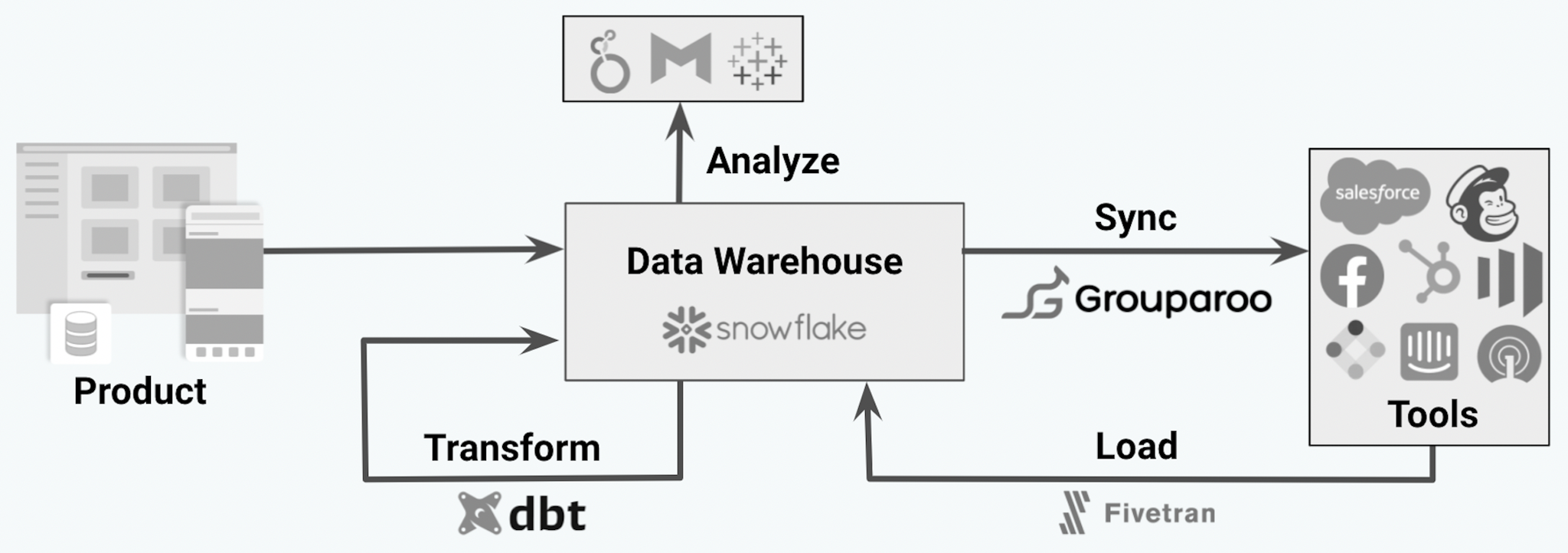
Over the last few years, there has been a shift in technology to deal with the exponential growth of data. The modern data stack is an approach and mindset regarding your data architecture. The most important concept is that you own the source of truth by storing everything of relevance to your business in your data warehouse. This warehouse sits in the middle of a pipeline that connects your product, analytics, and operational tools.

What is the modern data stack?
Maybe it sounds obvious that data should live in the data warehouse, but that has not always been the case.
In the past, there were often many sources of truth. Even if companies had a data warehouse with some related data, the Sales team often used Salesforce as their real foundation. Marketing did the same for Marketo.
They interacted with the data in those operational tools, so it was most important for them to be correct there. This remains true today, of course. However, this mindset often resulted in problems because all of the integrations built were point-to-point and ad hoc.
Why did the modern data stack emerge?
Problems arise when people can not trust or access the data.
Over time, these ad hoc solutions inevitably fail in some way. It surfaces when a Marketing team sends out an email promoting a product that the customer had already bought. Or Sales uses information on their dashboards to make a decision about an account, but the data isn’t accurate. If you want a list of all customers who’d made a purchase of over $300 in 2020 and were also email subscribers, for instance, it’s never as simple as just writing a single query. Data engineers end up pouring hours into fixing things every time a tool makes a minor change.
This situation leads to double-checking all the data every time, which slows the teams down. Worse, they would have to compare reports from each system and it never would line up just right. Modeling and analysis would become a nightmare. Forget about a cohesive dashboard. Even if you had data analysts, they couldn’t even do their job with the amount of cleaning up they had to do. Those discussions are fun, right?
Rally around a single source of truth
The solution is to create an infrastructure with that single source of truth: data warehouses. By storing everything in one place and making a continuous pipeline in and out, we can add trust back to the system. From there, we can share the data in ways that will please our teams, our customers, and our users.
Traditional data practices: Extract, Transform, Load
With your data in a unified location, there's no need to write costly join queries or hunt down data between sources.


Let’s take a look at the key components of the modern data stack working with the data warehouse:
- Product: Copy raw product data and events into your warehouse in their original form.
- Load: Extract and load (the EL in ELT) data from any other systems/tools into the warehouse as well using tools like Fivetran, Stitch, or Meltano. This data should also be in its original form and not transformed in any way.
- Transform: Combine and transform (Transformation is the T in ELT) the data within the warehouse into more usable schemas using tools like dbt.
- Analyze: Use these transformed tables in your business intelligence (BI) tools such as Looker, Mode, or Tableau.
- (New Opportunity) Sync: Extract, transform, and load (Reverse ETL) data from your warehouse back into the tools your business uses. Use the combined data to make these systems smarter with tools like Grouparoo.

Modern data stack: Sync your data to destinations
Reversing the ETL process means your data can be synced to the destinations you use it most.
The key here is that, at any given time, the data warehouse has a full picture of all business data -- from cookies to events to web analytics and more, all relevant data lives in one place. Everything else is about reading or writing that data. The learning curve is lower as you’re working around one central tool that feeds into all the others. A gravity forms around that source of truth and each new source or Destination makes all the rest better than before.
Why is the modern data stack important?
By centralizing your data initiatives into this single pipeline, you make the process more predictable and add trust as noted. You also unlock value, improve experiences, and do it all much more quickly and at scale.
Data ownership
Your data no longer uniquely lives in customer support, sales, or marketing tools. You now have the full record of what has been going on inside of those tools in a format that is queryable.
This makes it easier to generate business intelligence and combine data from across sources to gain the latest insights. For example, in Grouparoo, you could make a campaign based on customers that have spent $100 in your product, tend to open your emails, and have recently created a customer support ticket.
Owning the data also makes it easier to switch tools. It used to be that your data engineering team would have to write query after query and create an entire custom pipeline for each sales tool or CRM. With the modern data stack in 2021, you are no longer locked into the one CRM. While building new integrations from scratch requires a lot of engineering resources, Grouparoo will enable you to test a new integration out in minutes. Just add a new Destination.
Shared definitions
It’s time to stop having those conversations about why different tools are reporting different numbers. With one source of truth, we can define our metrics once and use those in multiple places. The executive dashboard and the Salesforce records use the same data.
Reverse ETL allows you to sync records and groups across your tools
You already have the data you need in your warehouse, Reverse ETLs allow you to sync that tailored data to tools such as Salesforce, Zendesk, or Marketo where you can put it to use.


By defining key concepts and models once, you can also improve the customer experience. You can define what it means to be a “high value, engaged customer” and see their numbers going up in your analytics tool. That’s great.
But now, Grouparoo allows you to take that concept to the next level and put the data into action. With a shared definition, that concept can be coordinated across the emails they receive, how quickly they are served by customer support, and even what is on their product dashboard. Anyone in your organization can check the data on their own terms. It all lines up, even with different types of reports and across different systems.
Speed and simplicity
When compared to the ad hoc solutions, there are less moving pieces in the modern data stack. The data flow is more predictable.
This simplicity leads to speed. There are less questions about how things work, so teams can operate more quickly and independently. That is a clear sign of a well oiled system. There is less to break and each tool has a clear job. For example, Grouparoo can be purely focused on connecting to your tools and making sure those syncs succeed, even in the face of inevitable API edge cases. There’s no need to build a new pipeline and write dozens of new lines of code when Snowflake changes their connection methods, for instance, we handle that for you.
If something does go wrong, it is easy to see which hand-off was missed. Is the data there to begin with? Did the dbt transform occur correctly? Grouparoo adds observability by logging all data sent to external tools. You can find the issue and fix that piece of the pipeline more quickly.
Grouparoo is a key piece of the modern data stack. Don’t stop at making great reports. Put your data into action. It’s easy for engineers to set up, and even easier for revenue teams to use. Get started today!
Get Started with Grouparoo
Start syncing your data with Grouparoo Cloud
Start Free TrialOr download and try our open source Community edition.