The Grouparoo Blog
If you’re a data analyst, data scientist, developer, or DB administrator you may have used, at some point, a non-relational database with flexible schemas. Well, I could list several advantages of a NoSQL solution over SQL-based databases and vice versa. However, the main focus of this post is to discuss a particular downside of MongoDB and a possible solution to go through it.
Recently, working on the Grouparoo source plugin for MongoDB, I came across a very simple requirement (simple, at least on SQL-based DBs with fixed schemas) which is to get all field names of a collection in order to provide to Grouparoo the available mapping possibilities. However, this is not a simple query on MongoDB as it should be and we’re going to see what is needed to achieve this.
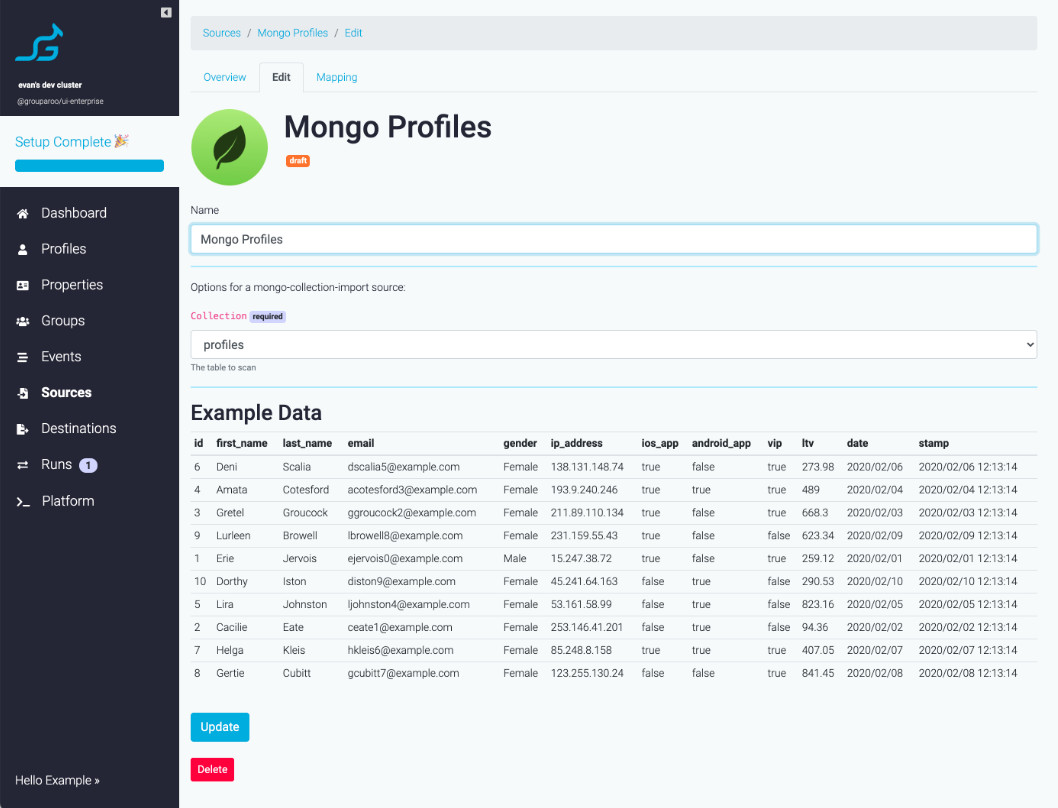
This image shows a data sample obtained using the all the fields retrieved from the "profiles" collection with the technique we're going to explore.
Before starting to get into the solution for this, let's discuss a couple of complicators of using a flexible schema database. Since there is no restriction for adding new fields it is impossible to guarantee that all documents have the same fields without reading all of them. Also, MongoDB allows related data to be nested within a single data structure and this fact increases the complexity of each document and, consequently, its queries. So, dealing with such a type of schema organization demands different thinking of how to store and retrieve data.
In our case, the information to be retrieved is all the field names including the nested ones. Ok, let’s split this problem into two parts: get all first-level fields and get all nested fields with dot notation (i.e. parent.child). For the first one, there are quite a few alternatives to reach the same results, such as:
Map-Reduce
Map-reduce operations use custom JavaScript functions to map, or associate, values to a key. If a key has multiple values mapped to it, the operation reduces the values for the key to a single object. Here is an example of how to get all first level fields of a collection using Map-Reduce:
db.runCommand({
mapreduce: "my_collection",
map: function () {
for (var key in this) {
emit(key, null);
}
},
reduce: function (key, stuff) {
return null;
},
out: "my_collection_keys",
});
After that, run the distinct command on the resulting collection to get a set containing all keys:
db.my_collection_keys.distinct("_id");
Mongo shell
Alternatively, you can get the same result from a mongo shell client:
var allKeys = {};
db.my_collection.find().forEach(function (doc) {
Object.keys(doc).forEach(function (key) {
allKeys[key] = 1;
});
});
Aggregation Pipeline
Also, you can use the aggregation pipeline which works with all drivers that support the aggregate framework. Within your aggregation pipeline, you can use the $sample and/or $limit in order to reduce the overhead for large collections.
const firstLevelFieldsResult = await db.my_collection.aggregate([
{ $project: { keyValue: { $objectToArray: "$$ROOT" } } },
{ $unwind: "$keyValue" },
{ $group: { _id: null, keys: { $addToSet: "$keyValue.k" } } },
]);
There are several other ways to achieve the same result, but the aggregation pipeline solution provides better performance (as compared to the map-reduce solution) and consistent usability than the other ones.
Great!! The first part of our problem is solved. Now, how can we get the nested fields? To solve this, we’re going to get deep into these nested fields and extract all the names one by one. Yup, you’re right, this is a very expensive task and we need to limit the number of documents to get into.
const docs = await db.my_collection.aggregate([
{ $sample: { size: 10 } },
{ $project: { _id: 0 } },
]);
The sample operation obtains 10 random documents (if available), and now we can go ahead and iterate over the resulting documents list and see if there are nested fields to grab the field names from.
for (const doc of docs) {
for (const [key, value] of Object.entries(doc)) {
if (
value !== null &&
typeof value === "object" &&
Object.keys(value).length > 0
) {
const nestedFields = getDocumentNestedFields(value, new Set(), key);
allFields = new Set() < string > [...allFields, ...nestedFields];
}
}
}
Since we know that the field has nested fields, in other words, the field type is “object” and there is at least one key, we need to extract the fields from it.
function getDocumentNestedFields(
document: any,
fields: Set<string>,
fieldName: string = ""
): Set<string> {
for (const [key, value] of Object.entries(document)) {
if (
value !== null &&
typeof value === "object" &&
Object.keys(value).length > 0
) {
getDocumentNestedFields(
value,
fields,
fieldName === "" ? key : `${fieldName}.${key}`
);
} else if (!Array.isArray(value)) {
fields.add(fieldName === "" ? key : `${fieldName}.${key}`);
}
}
return fields;
}
This function goes recursively into the nested fields and stacks the nested field names using the dot notation. An expected result for this function could be:
[field1, field2.nestedField1, field2.nestedField2, field3];
There you go! A simple way to get all first-level fields and, potentially, all nested fields, since we’re not covering all documents for performance reasons.
I hope you learned something new. See ya!


Tagged in Engineering
See all of Paulo Ouriques's posts.
Paulo is a passionate Software Engineer who loves to solve problems, especially those that have a positive impact on people's lives. Paulo is also an enthusiast of astronomy, physics and a great defender of scientific divulgation. Cooking and playing percussion are some of his hobbies.
Learn more about Paulo @ https://pauloouriques.com/


Get Started with Grouparoo
Start syncing your data with Grouparoo Cloud
Start Free TrialOr download and try our open source Community edition.