The Grouparoo Blog
So you have data in your product database and you need to synchronize it with something else.
Maybe you need to update a CRM or email system like Mailchimp, HubSpot, or Braze. Maybe it is more of an ETL thing and you need to move the data into Redshift or Snowflake.
In all cases, what we have here is a need for a sync engine. A sync engine monitors a source (your product database) for changes in order to process them in some way (update an external system). Specifically, the approach I am going to describe is called delta-based synchronization.
Building the common case for one is not particularly hard, but there are some tricks to keep in mind and tradeoffs to make.
Show me the code! If you prefer the executable kind of discussion, I have made a Github repo with these examples and more.
Setting up your source
In this article, I am going to assume that your product database is a relational one like MySQL. Except for minor syntax changes, Postgres and others would work as well.
The key part of delta-based synchronization is the "delta." That is, it must be possible to know what has changed in your database since the last sync. To do this, you will need a "high watermark." A watermark lets the sync engine know where to pick back up next time there is syncing to be done.
An example of a watermark could be an auto-incrementing id primary key in a table that is append-only in which rows are only added and not updated. In this case, the sync engine will remember the id it last saw. Then, next time it will start with the next one.
The most common type of watermark is a DATETIME column for when the row is updated. Many systems make this easy. For example, Ruby on Rails will automatically fill out a updated_at column if it exists. In this case, the sync engine will know the last time that it did a sync. Then, it will look for rows changed after that the next time it syncs.
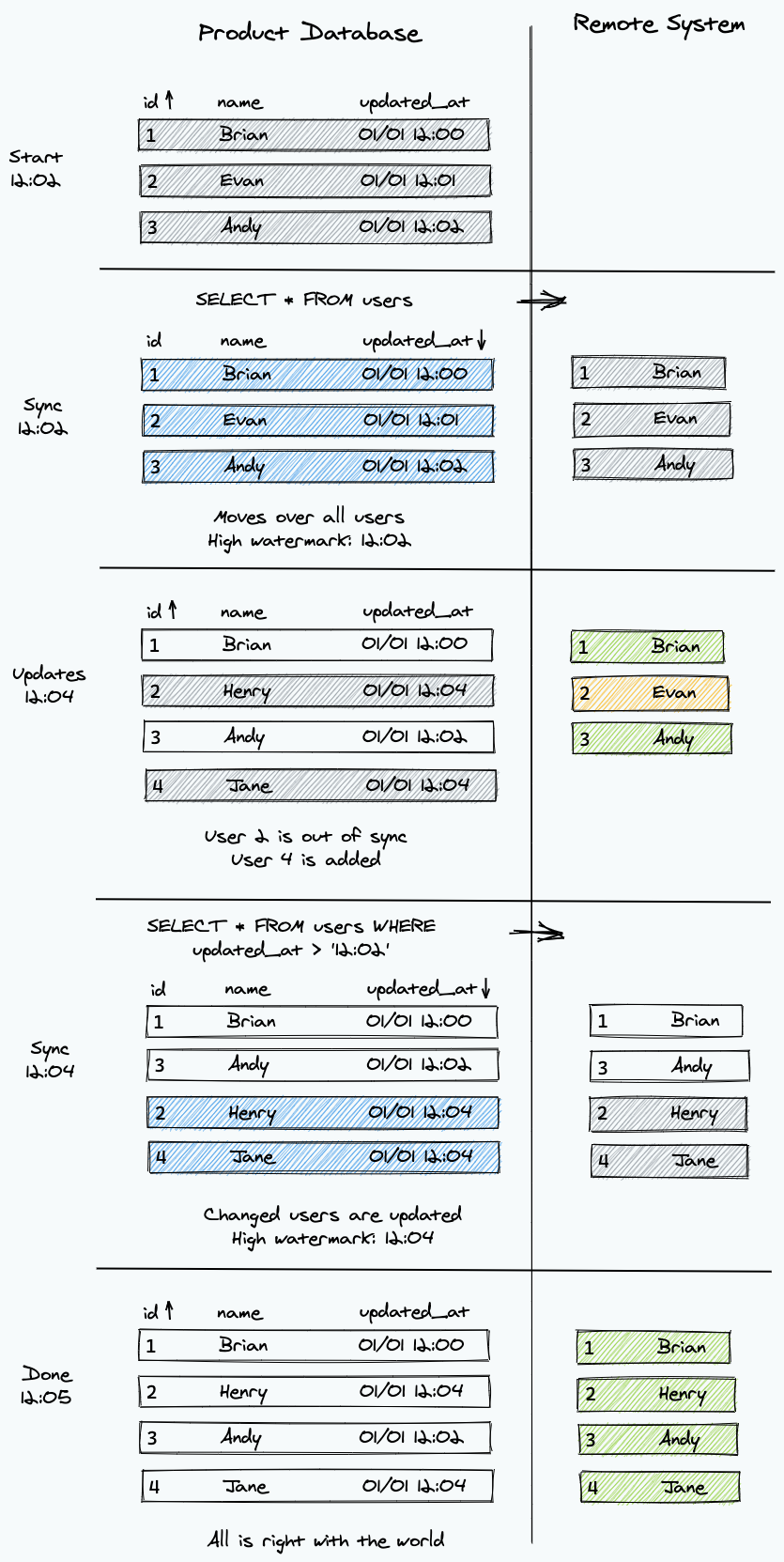
Auto-setting your watermark column
If a platform like Rails is setting your updated_at column, there are still cases when it doesn't happen all the time, resulting in things being out of sync. If you really want to get it right, I've seen it be effective to make an auto-updating column with no other meaning than just our sync timestamp.
In MySQL that looks like this:
ALTER TABLE users ADD COLUMN mysql_updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;
Postgres seems to need a trigger:
ALTER TABLE users ADD COLUMN postgres_updated_at TIMESTAMP DEFAULT 'now'::timestamp;
CREATE FUNCTION update_updated_at_column() RETURNS trigger
LANGUAGE plpgsql
AS $$
BEGIN
NEW.postgres_updated_at = NOW();
RETURN NEW;
END;
$$;
CREATE TRIGGER t1_updated_at_modtime BEFORE UPDATE ON t1 FOR EACH ROW EXECUTE PROCEDURE update_updated_at_column();
Simple algorithm
It is relatively straightforward to handle the most common case that a sync engine would encounter. Using the picture above, that code would look something like this:
// using node and sequelize
const watermark = await getWatermark();
let rows;
if (!watermark) {
// first time we've ever sync'd - get all rows
rows = await User.findAll();
} else {
rows = await User.findAll({
// otherwise, use watermark
where: {
updatedAt: {
[Op.gt]: watermark, // WHERE updatedAt > {watermark}
},
},
order: [["updatedAt", "ASC"]],
});
}
if (rows && rows.length > 0) {
for (const row of rows) {
await processRow(row);
}
const newWatermark = new Date(); // set to now
await setWatermark(newWatermark); // for next time
}
return true; // done!
One important piece of this code is to make sure we are sorting by the watermark (ascending). This guarantees that we keep moving that forward. This is why it's critical that the watermark always goes up (like a timestamp).
Watermark issues
There are few possible issues with how we used the watermark.
The first possible issue is that rows could have been changed between when we queried for changes and when we chose the watermark for next time. In a system that is writing changes often or when it takes a while to process each row, this is almost guaranteed to happen.
There is a version of this issue where there is a write in the same-ish millisecond right after the query. Because of this, we can use "greater than or equal to" with the watermark instead of just the "greater than" we had before. This will re-process the last item, but that is better than missing some.
The second possible issue is around coordinating time. Even if our engine can assume a watermark is always a time, we can't be sure that the time on the server running the sync engine lines up with the database and/or the code on the application setting the timestamps. Small drifts could lead to missed rows. Because of this, the sync engine should only use the values it gets from the database.
// using node and sequelize
const watermark = await getWatermark();
let rows;
if (!watermark) {
// first time we've ever sync'd - get all rows
rows = await User.findAll();
} else {
rows = await User.findAll({
// otherwise, use watermark
where: {
updatedAt: {
[Op.gte]: watermark, // WHERE updatedAt >= {watermark}
},
},
order: [["updatedAt", "ASC"]],
});
}
if (rows && rows.length > 0) {
for (const row of rows) {
await processRow(row);
}
const newWatermark = rows[rows.length - 1].updatedAt;
await setWatermark(newWatermark); // for next time
}
return true; // done!
This fixes both of those issues by using the values from the database itself.
Batching
Astute readers may have noticed that querying a list of all the users in a database might be a bit of a memory problem. Therefore, it's important to be able to do this in batches. However, this adds a whole new set of challenges.
The most common way to do this is via LIMIT and OFFSET in your watermark query. Let's say there is a batch size (limit) of 5 and there are 7 rows that need to be synced. We can process the first 5, leaving 2 more. Then, get the last 2 in the next batch.
The issue comes up if there is an update to one for the first ones we processed in between the queries.
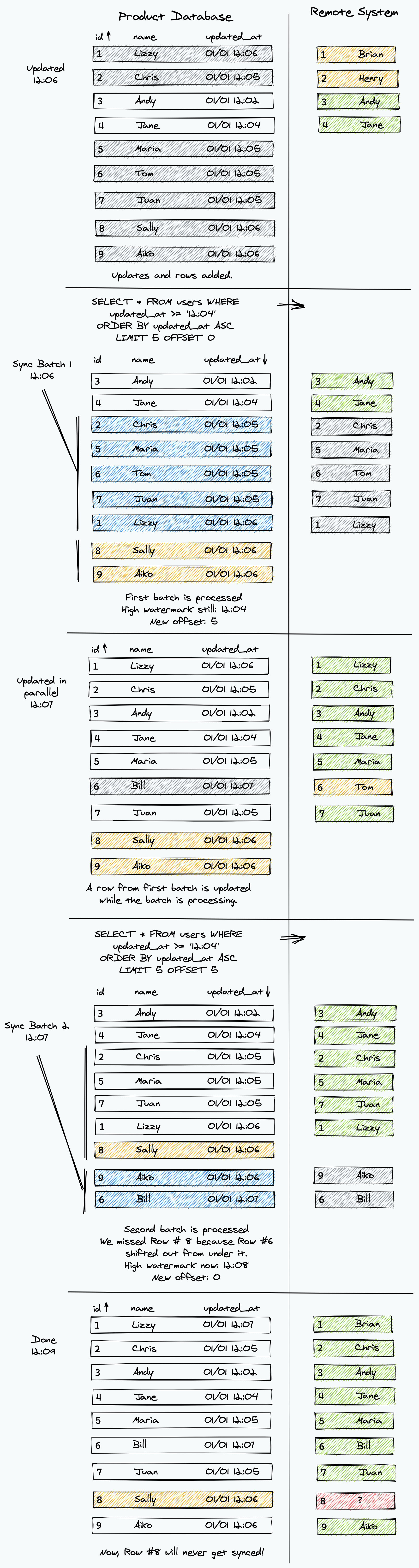
Because of how the sorting and offsets works, we miss one.
Here is a version of batching that only uses offsets when the there are more rows with the same timestamp as the batch size:
// using node and sequelize
const saved = await getWatermark();
const watermark = saved ? saved.watermark : null;
const oldOffset = saved ? saved.offset || 0 : null;
const sqlOptions = {
limit: batchSize,
offset: oldOffset,
order: [["updatedAt", "ASC"]],
};
if (watermark) {
sqlOptions.where = {
updatedAt: {
[Op.gte]: watermark, // WHERE updatedAt >= {watermark}
},
};
}
const rows = await User.findAll(sqlOptions);
if (!rows || rows.length === 0) {
return true;
} else {
for (const row of rows) {
await processRow(row);
}
const done = rows.length < batchSize; // is there more to be done?
const lastTime = rows[rows.length - 1].updatedAt.getTime();
let newOffset = 0;
if (!done && watermark === lastTime) {
// the last one was the same as the first, need to use offset
newOffset = oldOffset + batchSize;
}
await setWatermark({ watermark: lastTime, offset: newOffset });
return done;
}
There are several tradeoffs happening here: memory is preserved, but rows are more likely to be reprocessed. While the offset error is minimized, it can still exist. A suitable batch size will need to be chosen, ideally as large as possible.
In the Github repo, I explore different versions of these tradeoffs that produce completely new algorithms. Please check it out and let me know if there is an even better approach.


Tagged in Engineering
See all of Brian Leonard's posts.
Brian is the CEO and co-founder of Grouparoo, an open source data framework that easily connects your data to business tools. Brian is a leader and technologist who enjoys hanging out with his family, traveling, learning new things, and building software that makes people's lives easier.
Learn more about Brian @ https://www.linkedin.com/in/brianl429


Get Started with Grouparoo
Start syncing your data with Grouparoo Cloud
Start Free TrialOr download and try our open source Community edition.