The Grouparoo Blog
The State of Customer Data
The Modern Data Stack is all about making powerful marketing and sales decisions and performing impactful business analytics from a single source of truth. Customer Data Integration makes this possible.
Customers expect personalized experiences, connection, and relevancy. However, the fact of the matter is that without accurate, up-to-date data in a centralized location, your marketing team is missing out on opportunities. In fact, only 34% of marketing teams feel satisfied with their customer data solutions 1. And there’s reason to be skeptical of the data in your CRM -- over 91% of customer data sets in CRMs are incomplete2. Making decisions based on out of date or incomplete data leads to missed opportunities and lost revenue. CRM data integration and other forms of customer integration are crucial for being able to make wise decisions for your business.

What is Customer Data Integration
Customer Data Integration (CDI) is essentially the process of bringing together your disparate sources of data. Say you have customer data living in Intercom, sales data living in Paypal and Stripe, and support ticket data in Zendesk. But none of this data is connected. Each source is a data silo -- housing its own data but completely unaware of the contents or updates in other tools you use.
What you really want is a unified view of your data using Customer Data Integration so you can take action on it. Customer data integration here might include creating a data warehouse where you can house your accurate and complete dataset. One example of this would be creating a Postgres table that combines data from all of those sources.
Then, utilizing Reverse ETL, you can complete the cycle and push groups of data to the destinations you need it most by using tools such as Grouparoo’s Postgres Integration to connect with our Salesforce Integration, HubSpot Integration, or Marketo Integration.
Why Customer Data Integration Efforts Fail
Customer data integration can be tricky to get right. Building a custom pipeline with a data engineering team can be an exhausting effort. Many companies end up making one or more of the following mistakes:
You aren’t doing Customer Data Integration at all
One of the issues that gets in the way of data quality is data silos -- areas where data exists, but is separated from other, related data. So how do we get all of our customer data connected? The purpose of developing a customer data integration is to break down silos and get a unified view of the data you already have. From there, you can use Reverse ETL to extract and transform your data before getting it straight to the tools you use it in.
Surprise, surprise! If you aren’t actively trying to integrate your customer data across and between tools, you are probably already dealing with data silos -- and they likely have out-of-date data as well.
You have a CDI pipeline but it isn’t up to date
Perhaps you set up a customer data pipeline already and have all your data in a central location. How do you know your warehouse is up to date? You need to be sure that your customer data integration is re-importing your data regularly. This should account for what happens if a row is removed from your data source, if a row is changed, or if a row is added.
You have a CDI pipeline but the data is messy
In order to perform meaningful BI and Operational Analytics, you’ll need to make sure that your data is structured and normalized. Depending on how you’ve configured your customer data integration, there may or may not be a way to (a) check for data cleanliness/uniformity or (b) address it.
For example, take a look at this sample data set of customers who registered for an upcoming luncheon:
| id | first_name | last_name | email | company | meal choice | date |
|-----------|------------|------------|----------------------------|-------------|-------------|--------------------|
| ae1596cd | Erin | Peters | erin.peters@example.com | example co | 1 | 8/19/2021 10:44:21 |
| cd1220fb | Mario | Bravo | mario.bravo@example.com | Example Co. | 3 | 8/19/2021 10:53:42 |
| sl2090ch | Calvino | Nunes | cnunes@demo.com | Demo Co. | 2 | 8/19/2021 11:01:33 |
| as9300lf | Agnieszka | Trautman | atrautman@demo.com | Demo Co | 2 | 8/19/2021 11:05:43 |
| sd3820oe | Cassandra | Moreau | cassie.moreau@example.com | Example Co. | 1 | 8/19/2021 11:05:44 |
| kd2330as | Adriano | Masson | amasson@demo.com | Demo co | 2 | 8/19/2021 11:10:49 |
| sd2209ef | Mahya | Nazar | mahya.nazer@example.com | Example co | | 8/19/2021 13:23:11 |
| ae2203jf | Philip | Kristensen | pkristensen@demo.com | | 3 | 8/19/2021 14:21:52 |
| cd2330fb | Chloe | Weitzman | chloe.weitzman@example.com | Example Co. | | 8/19/2021 20:53:42 |
| asd2990fs | Alonzo | | aguitierrez@demo.com | Demo co | 2 | 8/19/2021 20:53:42 |
Several people are missing a meal choice. People completing the form were allowed to enter their own company’s name, so although there are only two companies represented here, there are six different company names -- and one is missing. Two people did not make a meal selection. If you query a data set like this, you end up with unintended results and an incomplete picture.
The best way to clean data is to normalize it before you even save it -- for instance, not allowing a user to submit their form without making a meal choice, making “company name” a drop down or having a validation/cleaning function before saving the data to your database. Though there are also libraries and custom scripts that can help with data cleaning as well.
Models of Customer Data Integration
The path forward here is to ensure that your Customer Data Integration solution can help keep your data both up-to-date and normalized. There are several models of Customer Data Integration that people use to do this. Depending on your business’ needs, these are the most common choices:
Data Consolidation
This is what most people picture when they hear the term “data integration”. Data consolidation is merging all of your data together into a single location such as a data warehouse. While consolidating, there may also be some data cleaning -- such as removing duplicate data, addressing missing data, etc.
Say you have purchase data coming from Stripe, leads coming from Marketo, and subscriber information coming from Mailchimp. Data consolidation would allow you to create a unified data warehouse with all of your contacts. From here, you can look at crossover data, such as high value newsletter subscribers or calculate conversion rate based on when your newsletter is sent.
There are many tools that can help with data consolidation, such as the open source tool airbyte which allows you to get a data pipeline up and running in minutes using their API or CLI tools. There are also larger enterprise options such as Fivetran that may be a great choice for very large data sets with many users.
There are also a few different ways to consolidate data, either ETL or ELT. Both are valid approaches, but with the rising popularity of fast, inexpensive warehouses like Snowflake and powerful transform tools like dbt, ELT is becoming the more common approach. You can learn more about the differences between ETL and ELT here.
Data Propagation
Data propagation is sending data directly to a destination -- or back and forth between the source and destination. Data propagation may seem similar to ETL or Reverse ETL, but with Data Propagation, data is never consolidated into a warehouse. This works well if there are relatively few sources and destinations. One drawback is that as your data scales, data propagation may be more difficult and complex to maintain.
Data Federation
Data federation is similar to a virtualized version of a data warehouse. Data is not actually moved or duplicated into a central location, but is accessed through views instead. These can be less expensive in terms of storage, but more expensive in processing. There is also the issue of downtime -- what happens if one of your sources is down when you’re virtualizing your data? Or the virtualization tool itself?
Data federation tends to be highly technical and doesn’t complete the step of getting data to where you need it. Having a singular, virtualized view of your data is great -- but to get the most out of your BI and operational analytics work, you want the data in the tools you’re already using.

Choosing a CDI method
Consider the following needs when looking into how to integration your customer data:
1. Scalability
A data warehouse can scale well with your data. Data Propagation may not work well if you begin to integrate new sources of data. The complexity will quickly outgrow the limits of data federation and you’ll be left, once again, with data silos. Likewise, a data federation model may become cumbersome.
However, with a data warehouse, it’s relatively simple using tools like airbyte to connect and combine new sources of data.
2. Reliability
With a data federation approach, you’re stuck hoping that each source is up and running and that your federation tool is running as well. Otherwise, you may end up with a piecemeal data set which, once again, limits your ability to perform any meaningful analytics or take action. Data propagation and data consolidation may be more reliable choices for this reason.
3. Actionability
Data warehouses enable you to perform operational analytics straight from the warehouse itself, or use a Reverse ETL tool to connect it with the tools you already use for analytics. With Data Propagation, where sources and destinations are combined piece by piece, it can be difficult to gather data across multiple sources. With a data warehouse, any of your data is ready for export right in one central location.
At Grouparoo, we’re fans of the Data Consolidation model to generate a data warehouse. A data warehouse will scale as your data and company grow. Its structure lends itself to reliability. And, with other tools from the modern data stack, you can make your data particularly actionable by sending it to the right destinations.
Cleaning Data before you Integrate
When processing data for integration, you need to make data cleaning decisions. As we looked at above, having an incomplete or inaccurate data set can interfere with your ability to get the most out of your warehouse:
Duplicate data
Consider what you’ll do with duplicate entries as well as what is considered a duplicate entry. How do you want your data set to handle when someone is both a subscriber and a purchaser? Should they be treated as two separate rows in your warehouse? Should they be merged into a single profile? What happens if a contact has a different address listed in Mailchimp versus Stripe? Deciding how to deal with duplicate data is an important part of making sure your data set is complete and accurate.
Empty/missing data
Empty and missing data can throw off calculations and comparisons. Should empty data be left empty? Be marked 0 or null or some other value by default? What happens if a row is deleted in one of your source databases -- should the profile in your warehouse also be deleted? Deciding what to do with empty and missing data ensures that you are moving towards data uniformity.
Uniformity
Again, ensuring data uniformity will allow you to make accurate calculations and comparisons. If you have purchase data, is all the data utilizing the same currency? How will you deal with timezones or dates globally? Data uniformity ensures that the comparisons and calculations you are performing on your data warehouse are accurate.
Once your data is cleansed and normalized, and you’ve integrated your data using one of the models outlined above, you can get to work with the analytics end of things. Hopefully you’ve gone with an approach that allows you to automate parts of the process, opening up resources for the analytics and action end of the process.
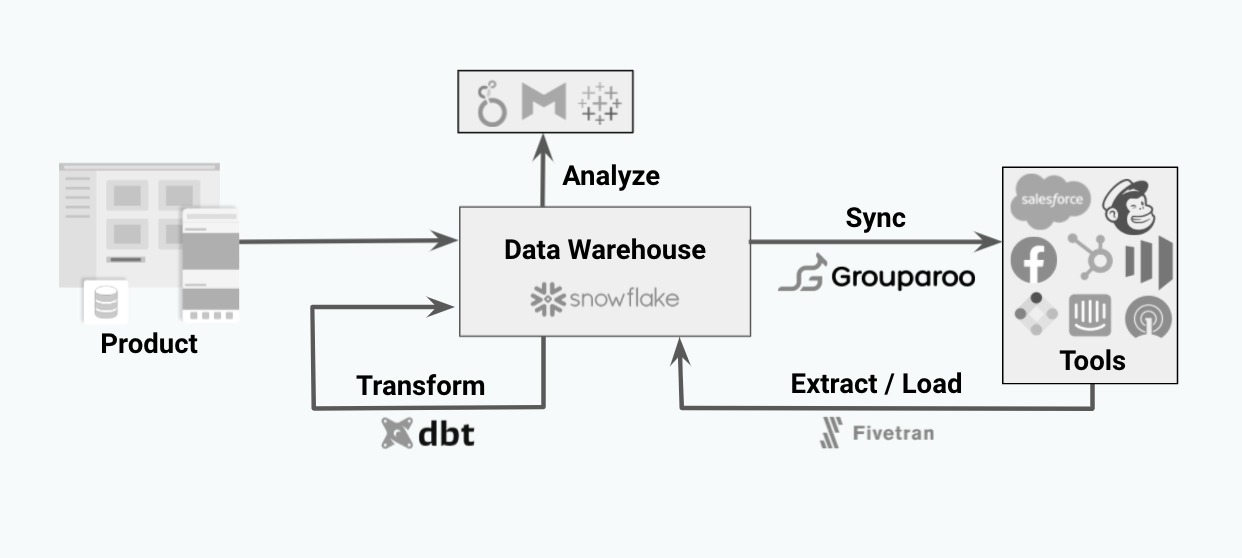
Completing the Cycle with the Modern Stack
At this point in the process, if you’ve gone with a Data Consolidation/Data Warehouse approach, you can utilize the modern data stack to take your data a step further. Reverse ETL tools provide a powerful way to transform your data and get it exactly where you’ll use it. You can calculate, filter, and send groups of subscribers to Mailchimp and marketing leads to Marketo for instance. The modern data stack is the most efficient way to keep your CRM synced with your source-of-truth data.
We’ve written many times before on the benefits of Reverse ETL, what Reverse ETL is, and why companies are moving towards a Reverse ETL approach for their data needs. A good data pipeline has a steady, reliable flow of data in as well as data out.
The purpose of Reverse ETL is to take your powerful data warehouse, which you can build with Customer Data Integration tools, transform/group it, and connect it to destinations of your choosing. With a good Reverse ETL process in place, you’ll have subscriber data up-to-date in Mailchimp, support data up-to-date in Zendesk, and groups of data such as “High value customers who subscribe to our email and have not made a purchase in 30 days” ready to go in Marketo.
TL;DR
Customer Data Integration can be a useful part of your modern data stack. What CDI data flow you choose will depend on your business’ needs. There are multiple decisions to make regarding data normalization and what method of CDI you use. Combined with Reverse ETL, Customer Data Integration gives you a powerful data pipeline to sync CRM data into and out of your warehouse, enabling you to make informed decisions and provide your customers with a more tailored and responsive experience.
- For more information on using data for marketing, see Salesforce's State of Marketing, 6th Ed - https://www.salesforce.com/content/dam/web/en_us/www/assets/pdf/salesforce-research-sixth-edition-state-of-marketing.pdf.↩
- For more information on data in CRM's, see Forbes article "How customer data drives marketing and sales performance"-- https://www.forbes.com/sites/forbestechcouncil/2020/10/30/how-customer-data-drives-marketing-and-sales-performance/?sh=50ebfe2b2053↩


Tagged in Engineering
See all of Teal Larson's posts.
Teal is a Full Stack Engineer at Grouparoo, an open source data framework that easily connects your data to business tools. Teal loves building products that solve real-world needs. If she isn't coding, Teal is probably riding her bike or nose-deep in a book
Learn more about Teal @ https://www.tealjulia.com


Get Started with Grouparoo
Start syncing your data with Grouparoo Cloud
Start Free TrialOr download and try our open source Community edition.