The Grouparoo Blog
The mission of many data teams is a very simple one. They seek to use data to help the business take smarter actions. The input is raw data from everywhere that touches the business. This includes many external sources, its own products, and various systems used for marketing, sales, and operations. The outputs often take the form of analysis, insights, models, and other usable mediums.
Because there are often many sources for the data, much of the work is often in data engineering. How can we best get the data into a usable form?
ETL and ELT are two approaches to getting data into a usable form for analysis and use. The end goal of both is to have data in a data warehouse ready to be leveraged.
As the similar initialisms might suggest, they are variations of each other; the main difference is the order in which they occur. These are the steps:
- Extract: Connect to the sources and read the valuable data. This could be from the product database, an event store, SaaS tools, or anything that has an API.
- Transform: The raw data is often not enough to be useful. The data must be transformed into a format that the business needs. This often includes normalization and rollups of similar data.
- Load: The end state in both cases is that the usable data is loaded and available in the data warehouse where it can be queried by business intelligence and operational tools.
The key difference between ETL and ELT is where the Transform step occurs. In ETL (extract, transform, load), transformations occur as part of the extraction and only the usable data is written to the warehouse. In ELT (extract, load, transform), the raw data is written to the warehouse and then separately transformed into usable data.
What is ETL?
For years, data engineers have been creating processes that extract, transform, and load data from external sources into their internal storage.
We arrange the common steps via a single recurring process running our code:
- Extract: Raw data is read from the sources in a recurring process.
- Transform: The code transforms the data into a usable format for consumption.
- Load: Data is loaded into the data warehouse to be leveraged.
In this ETL diagram, you can see the flow of data from sources through the ETL process into the data warehouse and beyond.
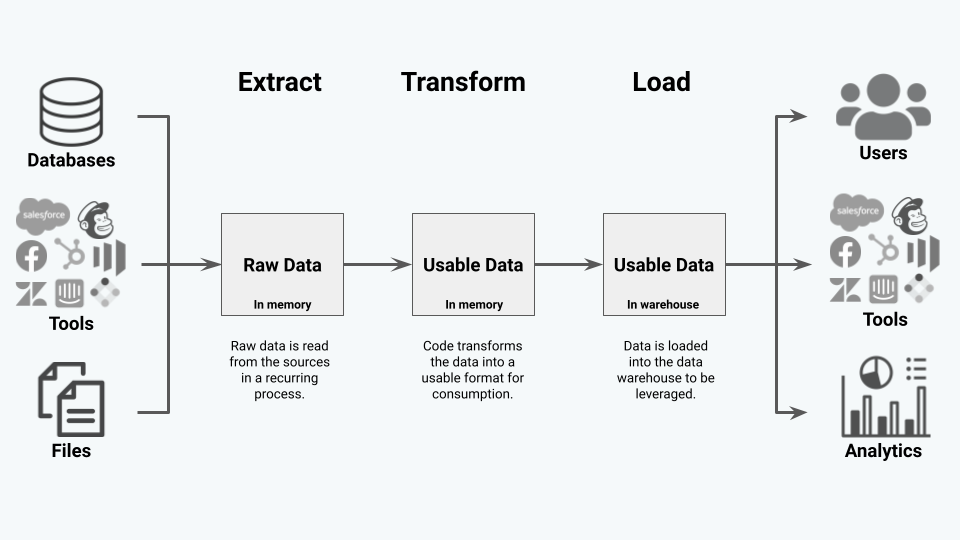
ETL Example
E: Extract
The first step is to connect to the source and to extract the relevant data from the source. Common sources include:
- Databases: The core of the data warehouse is often data extracted from the product database.
- Tools: Many marketing, sales, and success tools have important data about the customers. These tools often use the API access provided by each service.
- Files: Many types of other data exist. These can be CSVs with critical information, files in a data lake, or many other formats.
A recurring process runs code every so often. For example, we write some Python code that connects to Zendesk every hour and queries Zendesk for data. This code can then do whatever it wants with that data that has been extracted.
T: Transform
The next step is to transform that data into data that is usable by the business. ETL transformations take the data from each of these sources and turn them into useful metrics and data. Often the same code that was written for extracting the data will continue to process the data in the transform step. In the Zendesk example, we might be trying to serve metrics to our customer success team. So it might ask about the total number of tickets, those created in the last week, what percentage of those tickets have been handled, and so on.
L: Load
The last step is loading data into a data warehouse. Maybe this code is also keeping track of customers and the number of support tickets they have. It would ask the API for a list of customers who have had some recent activity. . For any changed customers, it would look up that customer in the warehouse, possibly by their email address, and make updates as necessary.
When the code is complete, the warehouse now contains the data that is meant to be served to the business users via analytics tools and SQL access.
In our example, the output would include:
- A
user_metricstable with a column for the number of tickets each has created - A
ticket_historytable with a row for each week and columns for the number of tickets created, processed, etc.
This data could also be written back to tools as required by another process. For example, we could write the ticket counts of each customer to Salesforce to help our Sales team understand who is struggling with our product. Because it is in the other direction, data engineers call this Reverse ETL.
What is ELT?
More recently, a new approach has gained popularity. ELT takes advantage of the reduced cost of warehouse storage to add more flexibility to the traditional ETL process.
We arrange the common steps but can achieve them via separate processes:
- Extract: Raw data is read from the sources in a recurring process.
- Load: The raw data is written directly to the warehouse without changes.
- Transform: Code or SQL views transform the data into a usable format.
In this ETL diagram, you can see the flow of data from sources through the ELT process into the data warehouse and beyond.
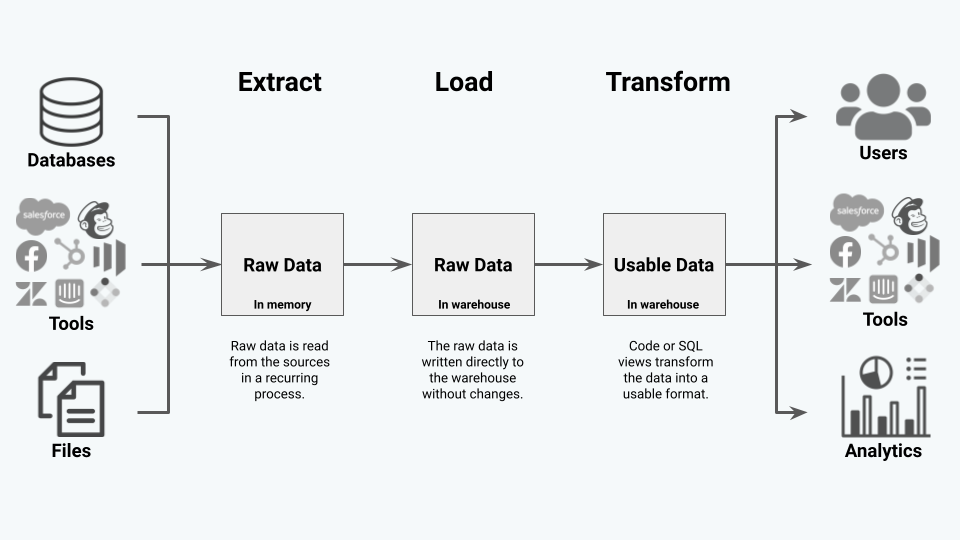
ELT Example
E: Extract
The first step is essentially the same as before. We connect to the appropriate source(s) and read the data. Recurring Python code still runs every hour. It is still asking questions via the API.
L: Load
The difference between ETL and ELT starts to reveal itself when we talk about what that code is going to ask of the API and what it’s going to do with the data. In the ELT case, it is not going to ask for any summary data. Instead, it will do its best to sync all of the raw data to the warehouse. It will ask for changes related to customers and tickets and write everything it can get to the warehouse, updating or creating rows as necessary. Then, it will stop processing.
Unlike before, this loading process will result in zendesk_customers and zendesk_tickets tables. These tables will have columns of all the raw information that was easy to extract from each of the models. In this case, it’s likely the zendesk_tickets table will reference zendesk_customers via a Zendesk-provided id. The zendesk_customers will likely have an email address, among other data.
T: Transform
With this raw data now available in the warehouse, a separate process can query and transform it to meet business requirements. For example, we could run code or a series of SQL statements that would count the number of opened and resolved tickets from zendesk_tickets and write them to the ticket_history table. Similarly we could make a mapping between our users and the Zendesk customers to be able to record how many tickets each had created.
At the end of both processes, the output would include:
- [EL] A
zendesk_customerstable with data directly from Zendesk - [EL] A
zendesk_ticketstable that references zendesk_customers about the current state of each ticket in that system. - [T] A
user_metricstable with a column for the number of tickets each has created - [T] A
ticket_historytable with a row for each week and columns for the number of tickets created, processed, etc.
The usable data tables (user_metrics, ticket_history) would be exactly the same as in the ETL example. This could be presented to users and integrated with other applications downstream in the same way.
ELT wins over ETL
If the output is not really any different for our data consumers, why would we choose the ELT approach?
ELT wins because it adds flexibility along multiple dimensions when we separate the raw data and the transformation of it.
First, it is important to note that writing a custom ETL process is very expensive in terms of data engineer time. With that in mind, what we want to do is minimize maintenance and what it means to respond to new requirements.
Less bugs
In the ELT case, the extraction process is only of the raw data and writing it to the warehouse. This is more reliable than the ELT case where more bugs will be created with the combination of reading the data and transforming it.
Compartmentalization
If there are new requirements, we often won’t need to touch the extraction process. We only need to update the transformation. And we’ll already have the data required. An ETL approach would mean running the process again over the whole history.
Accessibility
Because the raw data is in the warehouse, performing the transformation step using a tool like dbt only requires knowledge of SQL. Updating the ETL process also required Python skills. When more people can respond to new requirements, it’s better for everyone.
Self-service
Even if our team never prioritizes the transformation work, the raw data is still in the warehouse. Enterprising team members can query the data themselves to answer many of their own questions and analyze their data.
Tooling
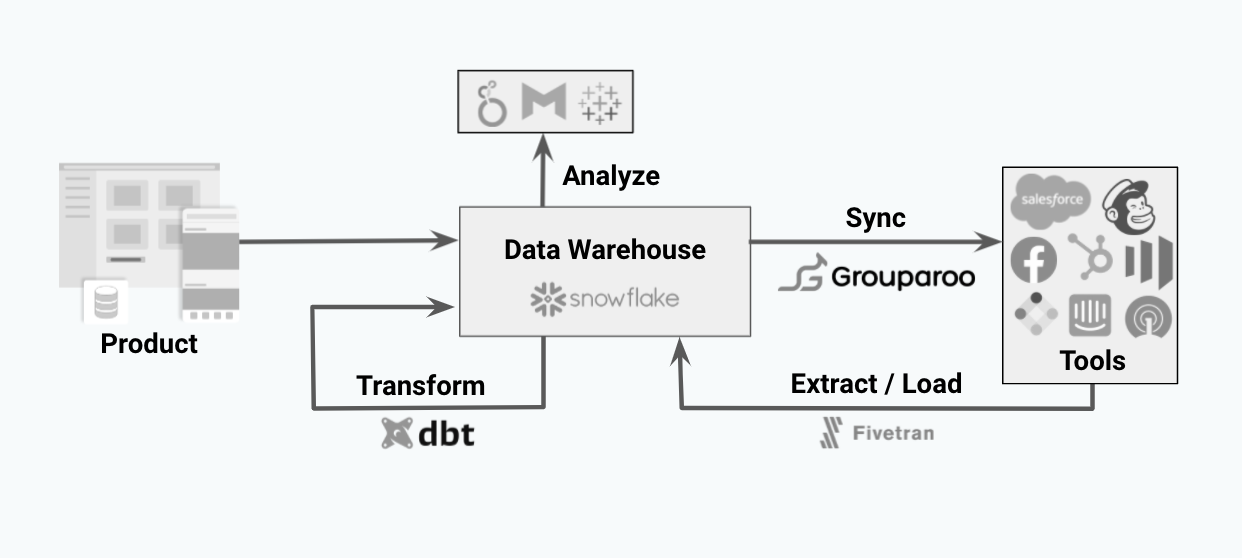
The ETL approach was completely custom to each business. In ELT however,the extraction process is the same across all businesses. This difference allowed tools like Fivetran or Airbyte to do standardize the process for us. These tools will take care of keeping our database up-to-date with all of the sources we have. On the other side of the pipeline, tools like Grouparoo can read from the warehouse and write back to our business applications. All that is left for our team to focus on is the data modeling custom to our business in the transformation step.
Why choose ETL?
The only reason that we would not choose ELT is if the storing of that raw data was a problem.
For example, it could be too costly. Even with the falling cost of warehouse storage, budget is still a concern. If we really only need the rollup of metrics and foresee no use for individual ticket information, storing all that ticket data might not be worth it.
The other concern is around data privacy. The raw data might contain information that we would rather never store in our warehouse. Extracting and transforming it in one step would alleviate that issue.
Additionally, if someone is already using ETL, the cost of switching to an ELT architecture could be quite high, so sticking with an ETL setup is better than having no ETL process at all.
The modern data stack
Most data teams in 2021 are opting into the ELT approach. This concept is at the core of the modern data stack. The right tools at each stage in the journey adds flexibility to get more leverage out of our data.


Tagged in Engineering Data
See all of Brian Leonard's posts.
Brian is the CEO and co-founder of Grouparoo, an open source data framework that easily connects your data to business tools. Brian is a leader and technologist who enjoys hanging out with his family, traveling, learning new things, and building software that makes people's lives easier.
Learn more about Brian @ https://www.linkedin.com/in/brianl429


Get Started with Grouparoo
Start syncing your data with Grouparoo Cloud
Start Free TrialOr download and try our open source Community edition.