The Grouparoo Blog
Don't Track Product Performance with Events
Tagged in Product Engineering MarketingBy Andy Jih on 2020-09-17
Many businesses have built great analytics products to help with tracking the actions your users are taking in your product (Mixpanel, Pendo, and Amplitude, to name a few). These products use an events-based data model where they track user behavior, usually client-side, so you can understand and visualize behavior like page views and button clicks. While this event-based model has been somewhat helpful at modeling high-level funnels and actions, we’ve learned over time that this model often creates more problems and challenges than they actually solve. Speaking as a product manager who has lobbied to integrate these kinds of analytics tools in the past, I’m sharing my thoughts on why events are usually wrong for tracking product usage.
You’re adding additional work every time you make changes to your product or want to track something new
When I worked at TaskRabbit, my fellow product managers and I prioritized integrating one of these event-based analytics tools into our products. The promise was very enticing: gaining visibility into how our users were using our apps, allowing us to analyze our funnels, and then driving product insights.
While this tool was great for tracking client-side actions like button clicks and page views, our funnel analyses inevitably needed to incorporate server-side actions for us to get the full picture. However, our engineering team was reluctant to add more events for a few reasons:
- Triggering events from the server-side meant additional work purely for tracking purposes.
- The data from this work was then duplicated as we also had Looker pointing to our data warehouse.
The engineers obliged due to my persistence, but I should have listened. Now, every new feature had an additional level of overhead and discussion: do we need to add a new event both server-side and client-side? How do we want to track it? How much time will it take to add this tracking? Do we really need to track this event?
Let’s say you do choose to instrument that event: doing so is an extra task that your engineering team works on, slowing down velocity. And then, be honest with yourself: will you actually look at data? What if you want to change or remove the event tracking? That’s another task for your eng team again.
And on the other end of the spectrum, let’s say you choose not to instrument the event. A month goes by and now you want to understand some behavior you’re seeing in your product. To diagnose the issue, you need funnel data that doesn’t exist. And even if you ask an engineer to instrument that event now, you won’t have data going back in time. You’re stuck.
You now have multiple data sources.
With events, you now have multiple data sources. Do you trust the data in Google Analytics/Amplitude and friends? Or do you trust your data warehouse? Analyzing your funnel now becomes fraught as you might end up combining data between different data sources. The data in your data warehouse will probably differ from the data that you see in Mixpanel, so you can either spend days if not weeks trying to debug the source of the discrepancy, or you can just accept that there’s some amount of variance (probably 10%-ish) between your data sources. Inevitably, you’ll likely pick one data source as your source of truth and just ignore or heavily discount the others.
Directional data is helpful for analysis, but not much else
As a result of all of these factors, event data is at best directional in nature. Your Data Science and Engineering teams won’t look at event data as a source of truth. They’ll look at your product data or data warehouse and trust that over event data almost always. As such, event data is at best useful for a high-level understanding for funnel performance and directional insights. But let’s say with those insights, you actually want to start personalizing and iterating on the user experience. Here’s where events fall down again. To personalize that user experience effectively, directional data can only take you so far-- you want to personalize that experience down to the specific user, and being able to identify that specific user by user ID or account requires source-of-truth data such as your product data or data warehouse.
Funnels often involve more than one user or actor
There are a number of different interaction types in products:
- Single user without any major server-side interactions or other interactions (e.g. a journaling app)
- Single user with server-side (booking a hotel room)
- Multi-user interactions (two-sided marketplaces like ride-sharing)
In the first instance, if the funnel consists entirely of actions that happen while the user is using your app or your website, then event-based analytics might work for you.
In most cases though, some processes or functions in your business actually happen once the user has “left the funnel”. As a result, either another user is taking an action or your product is doing something asynchronously. As a result, building this funnel becomes trickier, and relying purely on front-end events is fraught with inconsistencies. This use case happens more often than not. Are you notifying other users of a new post? Can a purchase be refunded or incomplete in some way? To really get the full picture of your customer’s experience, you need to consider more than just what buttons they clicked.
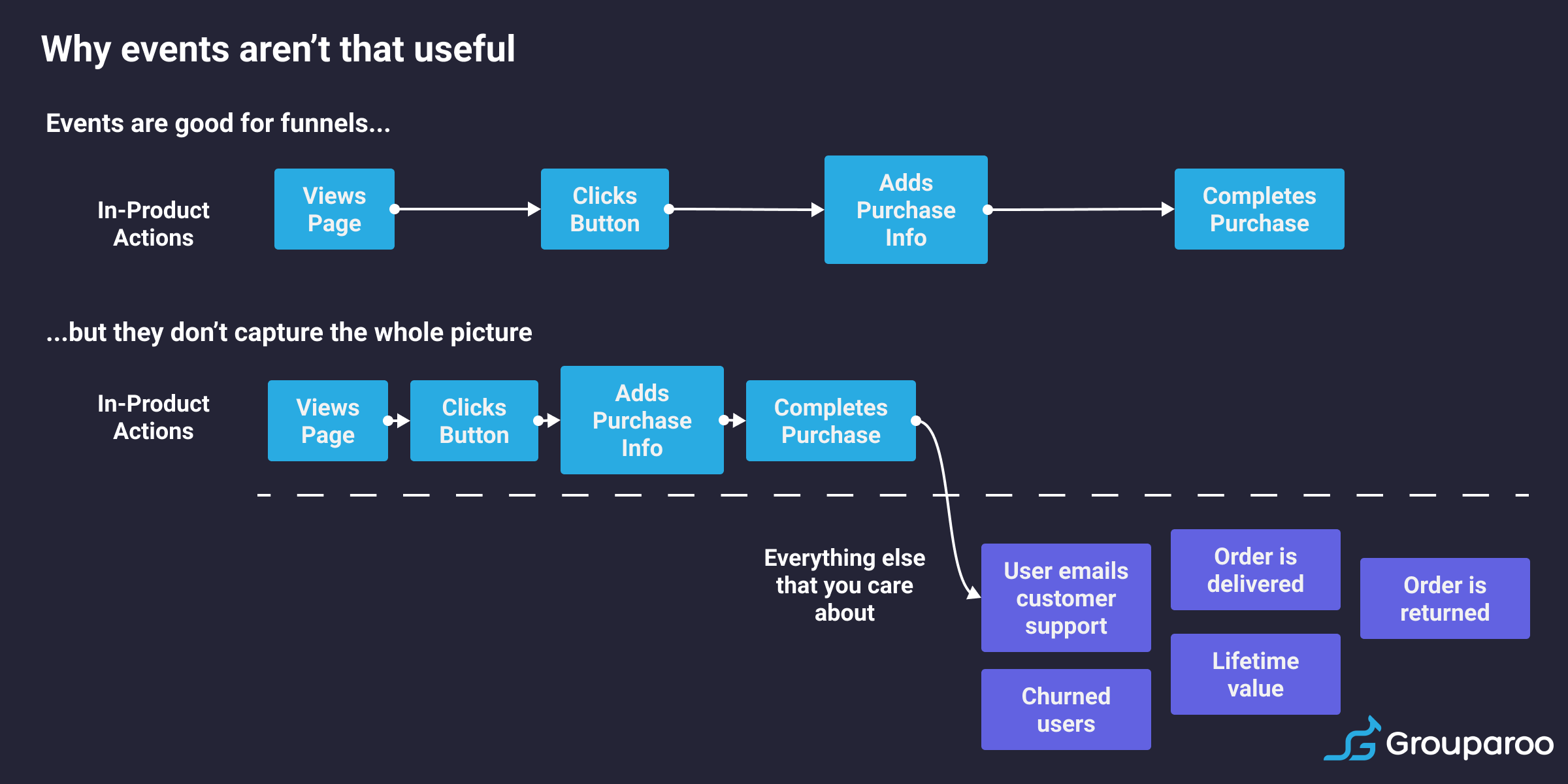
You only have history from when you first implemented events
One of the major challenges with events I mentioned earlier is that events are only useful from the date when you first implemented them. If you want to do analysis on how someone has gone through your funnel, you won’t have data going back through the beginning of your product’s history.
While some services are starting to support historical backfilling, normally these processes come at a significant cost, both in terms of price as well as engineering time.
If there’s an outage, you can’t recover lost data
If any of these event-based services ever has an outage, the event data during that time is lost forever. As a result, you can’t rely on event data for core product flows such as triggering emails or campaigns, or modifying the product UX. In order to remedy these situations, you’ll have to do substantial work to recover from your logs and de-duplicate any events that may have been captured. It’s a ton of work, and often not worth it.
Instead, use your source-of-truth data like your data warehouse or product database
Instead of relying on these event streams, use the data you already have and trust: your product database or data warehouse like Redshift. Your product is already running off of your product database and that’s the data that you trust. The open-source product we’ve built at Grouparoo allows you to pull in data from your source-of-truth data sources, segment your users into groups, and then send those user profiles and groups to 3rd party tools like email providers, customer support tools, and push providers. Our product is open-source and free, so feel free to read our docs to try it out, or reach out to us if you want to chat!


Tagged in Product Engineering Marketing
See all of Andy Jih's posts.
Andy is the COO and co-founder of Grouparoo, an open source data framework that easily connects your data to business tools. Andy loves building products that help people.
Learn more about Andy @ https://www.linkedin.com/in/andyjih


Get Started with Grouparoo
Start syncing your data with Grouparoo Cloud
Start Free TrialOr download and try our open source Community edition.