Grouparoo Network Topology
Last Updated: 2022-01-24Overview
When deploying Grouparoo, you will be creating 3 Tiers:
- Application Tier - The Grouparoo Application itself
- Data Tier - Storage for the Grouparoo Application
- Sources & Destinations External data which Grouparoo reads and writes.
Here is what a simple Grouparoo deployment looks like

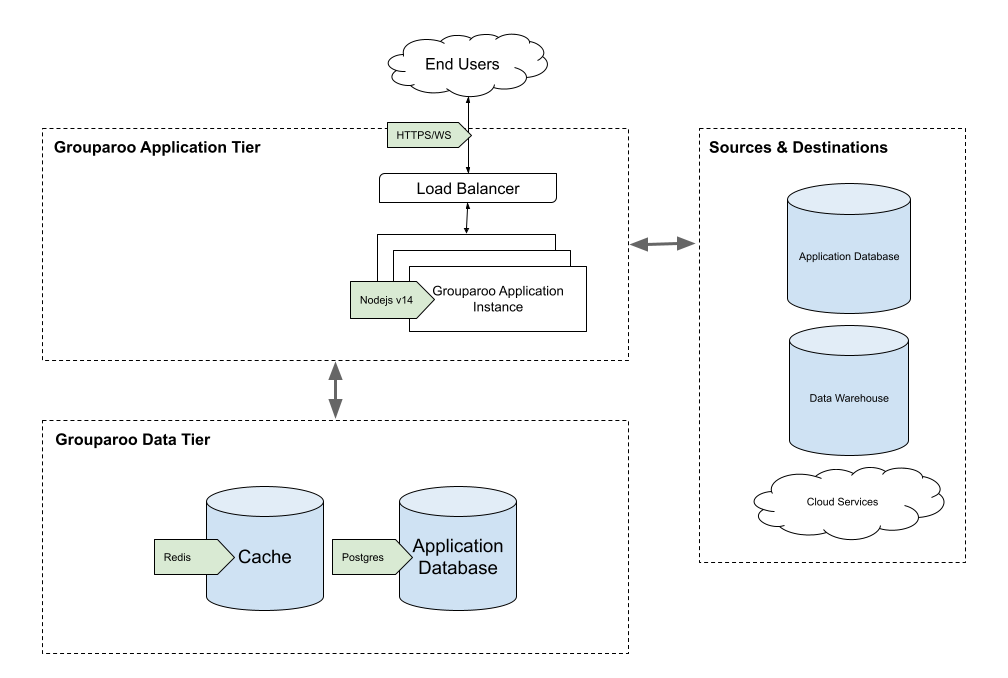
The Application tier can be as simple as a single instance of Grouparoo, or you can scale the application horizontally by adding more instances. An "instance" in this case is a single node.js process or docker image which runs the Grouparoo application. In the simplest case, each instance is both processing background jobs (WORKER) and serving the website and API requests (WEB_SERVER). This is configured via environment variables.
Sizing the Grouparoo Data Tier
Postgres
The Grouparoo application is write-heavy, making heavy use of a Postgres database to normalize and store copies of your data. We do this for a number of reasons, primarily:
- To support the joining of Record Properties for Records from multiple sources
- To create dynamic Groups from your Record's Profile Properties
- To provide an interactive user-interface to view and analyze your data
To that end, the Postgres database you assign Grouparoo will need to be:
- Large enough to hold all the data you intend to import
- Fast enough to quickly read and write data at the speed it is changing.
While a number of factors are at play when determining how "fast" to make your database, the following tips may help:
- The number one reason your Grouparoo application may be working slowly is a slow disk. Cloud vendors are notoriously stingy with the "hard drives" they provide by default on cloud databases. For example if your database is an AWS RDS instance, we recommend attaching at least 100GB of allocated storage. AWS scales IOPS along with the allocated storage.
- Ensure that you have enough Memory to keep a day's worth of data in working memory. For 1 million Records x 20 Properties, have at least 8GB of Ram allocated.
- Ensure that the database server is not in use by any other application.
- Ensure that all of your data can fit into the allocated database's disk.
You can tune Grouparoo's internal usage of the Postgres database further with batch size environment variables.
Redis
Grouparoo only uses redis as a temporary background queue, cache, and distributed lock. The Grouparoo Redis server does not need to be replicated or backed up, and Grouparoo will recover any lost data after a few minutes in the result of the Redis server going down. 256 megabytes of memory allocated to your redis server should be enough for most deployments. Grouparoo does not support Redis cluster.
Scaling Grouparoo
As your Grouparoo deployment gets larger, you may want to separate your worker instances from your web instances. You can accomplish this by running the same code in the same docker image, but running with different environment variables (WORKERS=0 vs WORKERS=10, for example). This allows different instances of the application to handle different workloads, and be scaled up or down accordingly. For example, if you have a large volume of data to process, but only a small number of users interacting with the site or API, you may want 5 worker instances but only 1 web instance.
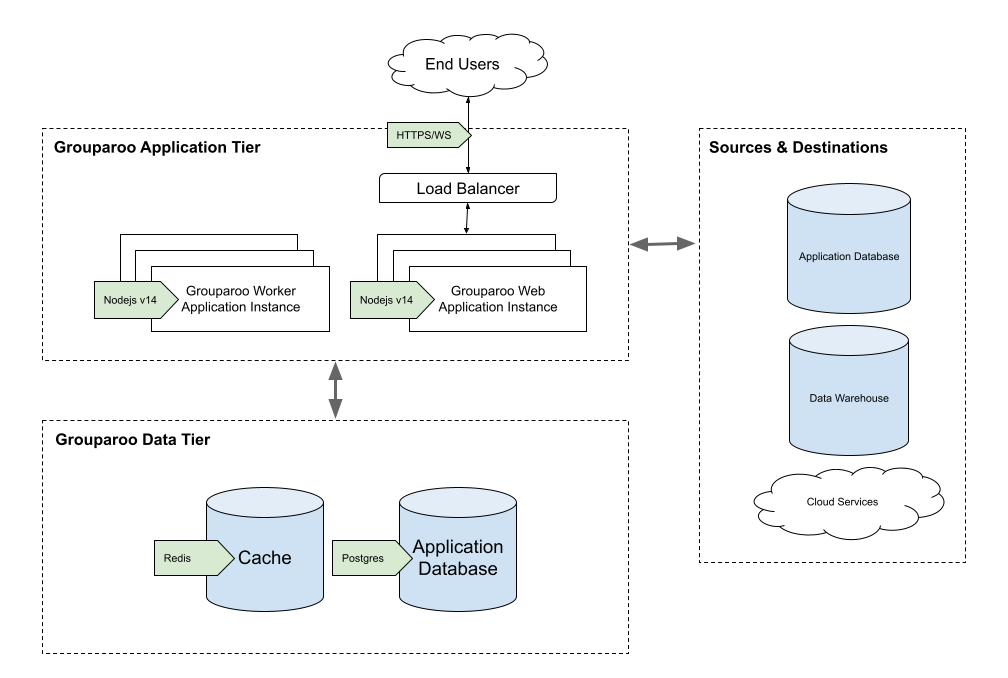
However, for most moderately-sized Grouparoo deployments, you won’t need to make this distinction - the same instance can be set up to run the workers and the website (WORKERS=5, WEB_SERVER=true, etc), as described in the simple case above
Learn More
To learn more about configuring Grouparoo to connect to the services within your topology, visit the Environment page.
To learn more about monitoring each tier, visit the Monitoring and Performance Page.
Having Problems?
If you are having trouble, visit the list of common issues or open a Github issue to get support.